pandas:【基礎】最初に知っておきたいこと
目次
前提
SeriesとDataFrameの2種類がある
Series
import numpy as np
import pandas as pd
sr = pd.Series(np.array([0,1]), name='a')
print(sr)
print(type(sr))
print(sr.shape)0 0 1 1 Name: a, dtype: int64 <class 'pandas.core.series.Series'> (2,)
- 一番左
- インデックス番号
- 列名は下に「Name」として表示されている
- Series作成オプションの「name」で指定した
- (2,)
- 1次元のデータになっている
- この表記が分からない場合は、下記参照
- 1次元のみ作成可能
- エラーメッセージ「ValueError: Data must be 1-dimensional」
DataFrame
import numpy as np
import pandas as pd
df = pd.DataFrame(np.arange(4).reshape(2,2), columns=['a','b'])
print(df)
print(type(df))
print(df.shape)a b 0 0 1 1 2 3 <class 'pandas.core.frame.DataFrame'> (2, 2)
- (2, 2)
- 2次元データ
SeriesとDataFrameは親戚
SeriesをつなげてDataFrameにする
import numpy as np
import pandas as pd
a = pd.Series(np.array([0,1]),name='a')
b = pd.Series(np.array([2,3]),name='b')
df = pd.concat([a,b], axis=1)
print(df)
print(type(df))a b 0 0 2 1 1 3 <class 'pandas.core.frame.DataFrame'>
- SeriesがDataFrameの基データになった
- pd.concatの説明
DataFrameが1列になるとSeriesになる
import numpy as np
import pandas as pd
df = pd.DataFrame(np.arange(4).reshape(2,2),columns=['a','b'])
a = df['a']
print(a)
print(type(a))
print(a.shape)0 0 1 2 Name: a, dtype: int64 <class 'pandas.core.series.Series'> (2,)
- DataFrameから1列取り出すとSeriesになった(暗黙ルール)
- よって親戚みたいなものです
構成要素
まずは全体
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.choice(10,(3,4)), columns=['a','b','c','d'])
print(df)
print(df.shape)a b c d 0 8 8 3 7 1 7 0 4 2 2 5 2 2 2 (3, 4)
- Excel表のようなデータ
- データフレームのサイズは(3,4)
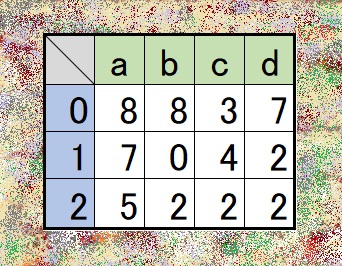
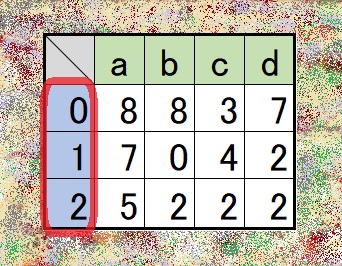
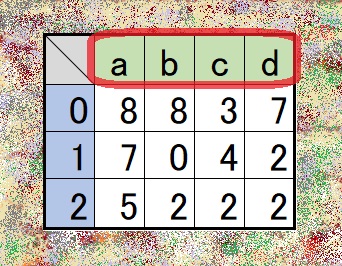
- 構成要素
- 一番左 …… インデックス列(index)
- 一番上 …… 列名(カラム)
- 真ん中 …… データ
インデックス列(axis=0)
説明
- 一番左の列
- データに自動で振られた行番号
- ある列をインデックス列に指定することもできる
- 別記事に説明記載
- axis=0と言うとインデックス列のこと(暗黙ルール)
実際に見てみる
print(df.index)
print(df.index.start)
print(df.index.stop)
print(df.index.step)RangeIndex(start=0, stop=3, step=1) 0 3 1
- RangeIndex型になっている
- 中身は順番に並んだ番号の固まり
- 含まれる情報
- start …… 最初の数字
- stop …… 繰り返しの最後の数字(この数字は含まない)
- step …… 次の数字までにいくつ足すか
- インデックス番号で行データを抽出できるが、指定方法に特徴あり
- 例えば、
- ×:df[0]
- 〇:df[df.index==0]
- これはブールインデックス参照(暗黙ルール)
- 説明は後述
- 例えば、
カラム(axis=1)
説明
- 次のいずれか
- データに自動で振られた列番号
- データフレーム作成時などで指定した列名
- axis=1と言うとカラムのこと(暗黙ルール)
- 列データによりいくつかの抽出方法がある
- 例えば、
- df['a’]、df[0]、df.a
- 別記事に説明記載
- 例えば、
実際に見てみる
print(df.columns)
print(df.keys())Index(['a', 'b', 'c', 'd'], dtype='object') Index(['a', 'b', 'c', 'd'], dtype='object')
- リストみたいな感じ
- columnsかkeys()のどちらかで取り出し
- 列番号を指定しないことも可能
- インデックス列と違ったものとして理解しておく
- 参照方法や扱い方が異なる
データ部分
データ部分取り出し
print(df.values)[[8 8 3 7] [7 0 4 2] [5 2 2 2]]
- NumPy配列(ndarray)に変換するコマンドでデータ部分は取り出し可能
- 補足
- 「.values」メソッドはindexやcolumnsに対しても利用できる一般的なコマンド
- valuesを使うとndarrayになる(暗黙ルール)
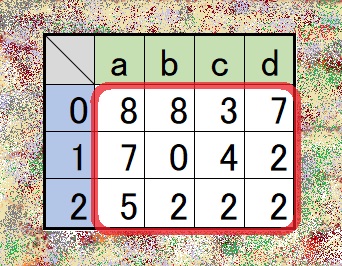
行データ参照の基本
ブールインデックス参照
- 行データ参照方式はブールインデックス参照(暗黙ルール)
- bool型を引数にして取り出す
- 参考:ブールインデックス参照について
例
データ作成
import pandas as pd
df = pd.DataFrame({'id':['001','002','003'],'key':['x','y','z'],'value':[100,200,300],'path':['aa','bb','cc']})
print(df)id key value path 0 001 x 100 aa 1 002 y 200 bb 2 003 z 300 cc
- Pythonのディクショナリ型を使ってデータ作成
データ参照
df[[True,False,True]]id key value path 0 001 x 100 aa 2 003 z 300 cc
- [True,False,True]を上から順と考える
- 「True」のみ抽出される
- 行のインデックス番号が0,2のデータが抽出される
- 使いにくい?
- ブールインデックス参照以外にも参照方法はある
- でも、高速
- なので、基本の動作は頭に入れておく
- 参考
- ブールインデックス参照に関する詳細説明
