Pytorchの利用例(DCGANサンプルコード)
人工知能(AI)を効率よく開発するため、フレームワークが利用されます。E資格では複数のフレームワークから選択できますが、ここではPytorchを例にします。フレームワークが強力なツールであることがより実感できるよう、PytorchのDCGAN チュートリアルを参考にして、その利用方法を見ていきます。実装済みのアルゴリズムをパズルのように組み合わせ、少ないコードでデータ前処理やAIモデルをコーディングします。

パズルのピースごと確認すれば理解できます
はじめに
DCGANについて
正式名は「Deep Convolutional GAN」です。また、GANも「Generative Adversarial Network」の略で横文字がずらっと並びますが、簡単に『画像生成にディープラーニング(+畳み込み)を使っている』ぐらいの理解で進めます。
データ準備
◆CelebAデータセットをダウンロードして解凍します。
- 新規フォルダ(以下では「image」)作成
- img_align_celeba.zipをダウンロードして解凍
(多いので解凍途中でキャンセル。画像は1,000件) - 「image」配下に解凍した「img_align_celeba」を配置
フォルダ構成は「torchvision.datasets」の仕様に合わせます。指定したディレクトリ配下のサブフォルダすべてから画像を拾ってきます。
◆解凍したファイルを確認します。
import glob
glob.glob('./image/img_align_celeba/00000[1-3]*')['./image/img_align_celeba\\000001.jpg',
'./image/img_align_celeba\\000002.jpg',
'./image/img_align_celeba\\000003.jpg']
--
1000件(000001.jpg~001000.jpg)のうち先頭3件を確認。
※Windows環境のため、パス区切りが一部「\\」
Pytorchインストール(まだの場合)
ローカル開発環境の場合のみインストールします(「Google Colaboratory」の場合は不要)。
- Pytorch公式HPにアクセス
- ページ中段「INSTALL PYTORCH」
- 「Your OS」など選択(背景赤になる)
- 「Run this Command:」のコマンドをコピー
- 「Anaconda Prompt」にペーストして実行
※「Anaconda(Miniconda)」での利用を想定

インストールされていないことはエラーで気づきますが、以下のコマンドでも確認できます。
conda list | moreインストール済みであれば、一覧に表示される。
※「Enter」でコマ送り
「スペース」でページ送り
「q」で終了
--
・
pytorch 1.8.1 py3.8_cpu_0 [cpuonly] pytorch
・
・
torchaudio 0.8.1 pypi_0 pypi
torchvision 0.9.1+cpu pypi_0 pypi
・
・
メイン
Pytorchのコード
DCGANの「Discriminator」をピース(畳み込み:Conv2d)の組み合わせで作り、前処理した画像データを投入して結果を観察します。フレームワークを使えば、(今回はGANの一部の機能ですが)簡単に作れてしまいます。
Discriminator(識別器)は、Generator(生成器)の作成したフェイク画像か、本物の画像かを”識別”する役割を持ちます。
1.初期設定
◆ライブラリをインポートします。
#入門編で利用したもの
import numpy as np
import matplotlib.pyplot as plt
#今回の初級編で追加したもの
import torch
import torch.nn as nn
import torchvision.datasets as dset
import torchvision.transforms as transforms(出力なし)
--
通常は利用するものまとめて書きます。
今回は分かりやすさを優先し、必要になれば追加しています。
「import」エラーになった場合、『Pytorchインストール』を参照してください。
◆初期値を設定します。
image_size = 64
batch_size = 16(出力なし)
--
後ほど次のように使います。
image_size:前処理で変更(178x218 → 64x64)
batch_size:まとめて処理する件数(画像16件)
2.前処理
◆フォルダから読み込んで画像の前処理をします。
# Create the dataset
dataset = dset.ImageFolder(root='./image/',
transform=transforms.Compose([
transforms.Resize(image_size),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
]))
print('画像件数:'+str(len(dataset.imgs)))
a = [print(dataset.imgs[i][0]) for i in range(3)] #先頭の3件をきれいに表示画像件数:1000
./image/img_align_celeba\000001.jpg
./image/img_align_celeba\000002.jpg
./image/img_align_celeba\000003.jpg
--
変数[dataset]に1000件(枚)の画像が入りました。
それだけではありません。
「transform」に注目です。transforms.Compose([xx, xx, …])として前処理をつなげると、すべての画像を一度に編集します。今回は3つ書いています。
- Resize…「178×218」→「64×64」
- CenterCrop…中心から「64×64」に切り抜き
- ToTensor…画像編集の決まり事
3.取り出し
◆前処理した「dataset」を取り出せるようにします。
どのように取り出すか指定できます。
# Create the dataloader
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size)
type(dataloader)torch.utils.data.dataloader.DataLoader
--
Pythonの「generator」型です。
16件(初期値設定した「batch_size」)ずつ画像を取り出します。
※他に「shuffle=True(ランダムに取り出す)」などのオプションがあります。
◆1セット(16件)取り出します。
for (data, labels) in dataloader:
break
#data, labels = next(iter(dataloader)) #またはこちらでもOK
print(data.shape)torch.Size([16, 3, 64, 64])
--
データ数 :16件(枚)
チャネル数: 3つ(RGB)
サイズ :64px × 64px
※この「data」を後ほど「Discriminator」に投入します。
◆先頭の1枚で、前処理の効果を確認します。
from PIL import Image #Pillowを利用
im = Image.open('./image/img_align_celeba/000001.jpg') #先頭の画像
#左の窓にフォルダの画像
plt.subplot(121)
plt.imshow(im)
#右の窓に加工(前処理)した画像
plt.subplot(122)
plt.imshow(data[0].numpy().transpose(1,2,0)) #Numpyに型変換してからtransposeメソッド利用
plt.show()(画像表示)
--
画像は粗く正方形に加工されました。
見た目の大きさだけでなく、目盛りにも注目。

「178 x 218=38,804」→「64 x 64=4,096」で1/9ぐらいになります。学習データを数万件とすると、この前処理は重要です。他に、画像を並べて表示する便利なツールもあります。
4.モデル作成
◆変数設定
nc = 3 # Number of channels in the training images. For color images this is 3
ndf = 64 # Size of feature maps in discriminator
(出力なし)
--
nc:RGBの3つ
ndf:畳み込みで使う特徴マップサイズ(JDLA認定プログラムなどで学ぶところ)
◆モデル作成(Discriminatorの機能をCNNで実装)
class Discriminator(nn.Module):
def __init__(self, ):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
nn.Conv2d( nc, ndf * 1, 4, 2, 1, bias=False),
nn.Conv2d( ndf * 1, ndf * 2, 4, 2, 1, bias=False),
nn.Conv2d( ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.Conv2d( ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.Conv2d( ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)
(出力なし)
--
実際のコードから骨組み部分を抜き出しました。
識別器の本来の能力を発揮するには、原文コードに合わせます。
※ピースを組み合わせていると表現したところです
いくつも数字が並んでいますが、変更せずコピペ、ありがたく使わせてもらいます。この数値、この階層(5つ)を見つけ出したところが研究成果です。「ndf」はハイパーパラメータなので、任意に変更できます。
5.モデルの実行
◆実体を作ります。
netD = Discriminator() #インスタンス作成
print(netD)Discriminator(
(main): Sequential(
(0): Conv2d(3, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(2): Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(3): Conv2d(256, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(4): Conv2d(512, 1, kernel_size=(4, 4), stride=(1, 1), bias=False)
(5): Sigmoid()
)
)
--
今回作成したモデルの具体的な内容が明らかになりました。
(こうなるように設計した)
◆識別処理実行
#データをモデルに投入
output = netD(data).view(-1)
#確認
print('before:'+str(data.shape)) #入力データ
print(' after:'+str(output.shape)) #モデル投入後before:torch.Size([16, 3, 64, 64])
after:torch.Size([16])
--
モデルに通すと4次元テンソルが1次元テンソルに変化
◆最後の確認
print(output)tensor([0.5003, 0.5016, 0.5038, 0.4976, 0.4989, 0.5005, 0.5041, 0.5017, 0.5001,
0.4998, 0.4978, 0.5007, 0.5028, 0.4992, 0.5021, 0.5003],
grad_fn=)
--
16個の画像が16個の数値(確率値)になりました。
この確率値がそれぞれの画像の本物/偽物の数値化です。
※本当はもう少し数学的ですが、本物か偽物か見分けがつかない(50%-50%)となる生成画像を目指します
生成画像サンプル
データ数1万件で画像16枚(batch_size=16)を生成しました。受講したJDLA認定プログラムの最終課題(卒論みたいなもの)で取り組んだものです。




生成画像の元は乱数(砂嵐)で、徐々に人物の顔に変わります。学習データもデータセットからランダムに取り出されます。環境により浮動小数点の有効桁数も異なり、学習パラメータも変更できます。つまり、同じ画像はこの世に存在しないことになります。
補足
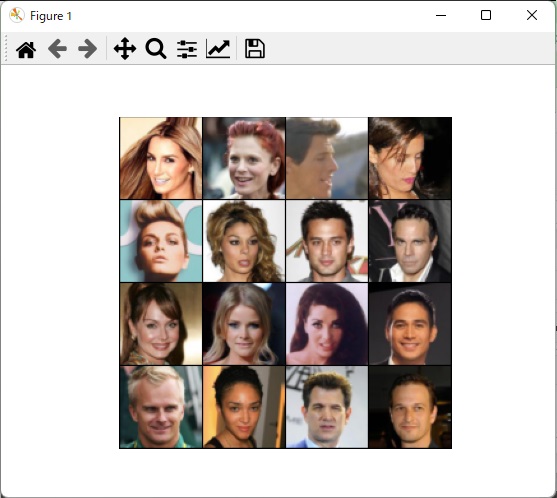
画像を並べて表示するツール
これもPytorchのチュートリアルに記載されています。
import torchvision.utils as vutils
plt.figure()
plt.axis("off") #目盛りなし
pre = data.shape #確認用
img = vutils.make_grid(data, nrow=4, padding=1, normalize=True) #4行で格子上に並べる。線幅は1
before = img.shape #確認用
img = np.transpose(img, (1,2,0)) #TensorにNumpyのtransposeを適用(さっきと違うやり方)
after = img.shape #確認用
plt.imshow(img)
plt.show()
print(' pre:'+str(pre)) #最初の並び
print('before:'+str(before)) #transpose前の並び
print(' after:'+str(after)) #transpose後の並び(画像表示)
pre:torch.Size([16, 3, 64, 64])
before:torch.Size([3, 261, 261])
after:torch.Size([261, 261, 3])
--
表示したい形に少しずつ整形しています。
torch.Size([16, 3, 64, 64]) #1回分の「dataset」
↓
torch.Size([3, 261, 261]) #16枚をつなぎ合わせ1枚に
↓
torch.Size([261, 261, 3]) #Matplotlib(行、列、カラー)の順に変更
※261=64 x 4 + 5
以上